Stable Diffusion模型基础结构原理
Stable Diffusion模型基础结构原理——Latent Diffusion
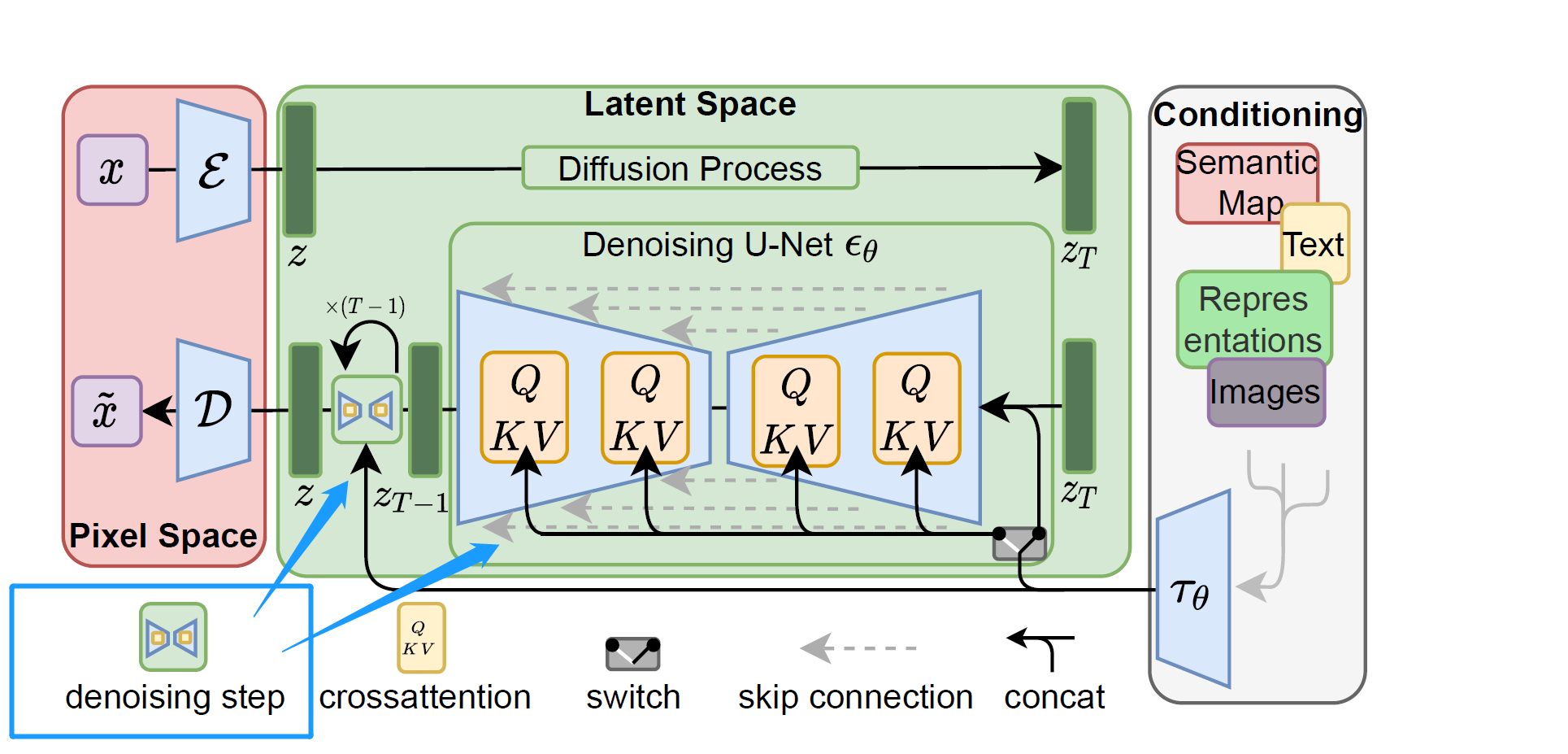
提到Stable Diffusion,就不得不提到latent diffusion,也就是下面的这张图
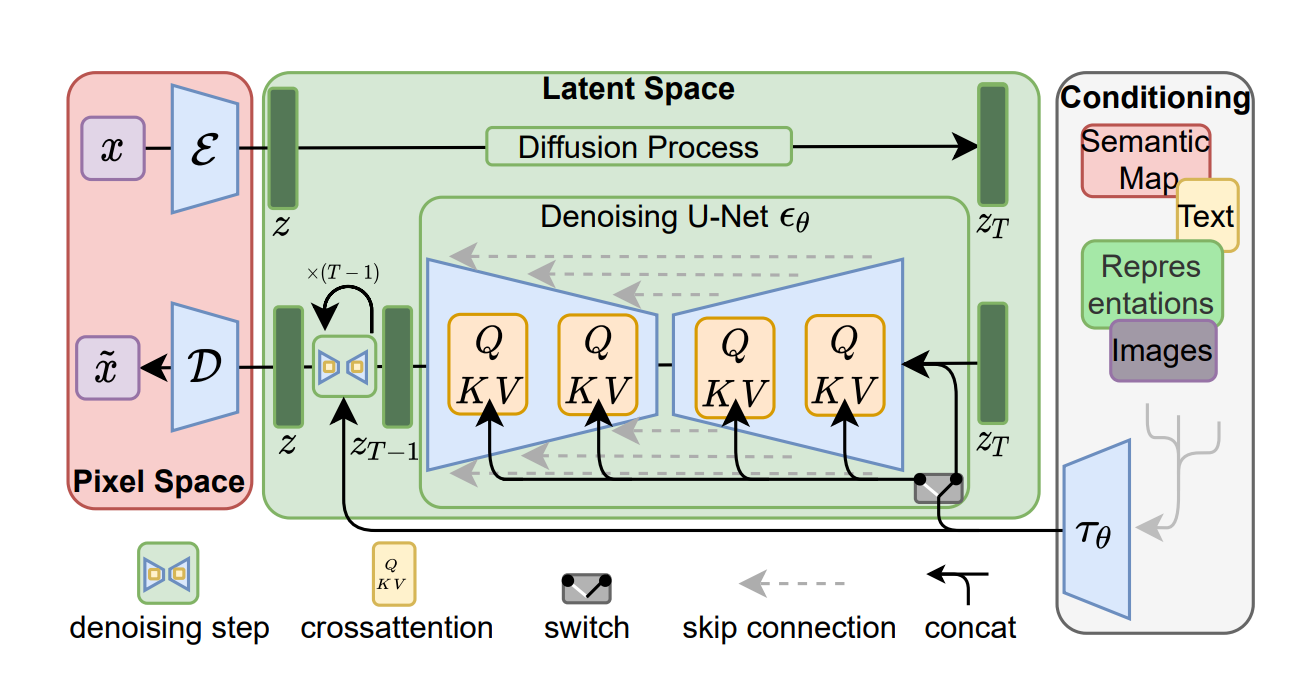
Stable diffusion是一个基于Latent Diffusion Models(潜在扩散模型,LDMs)的文图生成(text-to-image)模型。具体来说,得益于Stability AI的计算资源支持和LAION的数据资源支持,Stable Diffusion在LAION-5B的一个子集上训练了一个Latent Diffusion Models,该模型专门用于文图生成。
Pixel Space
Pixel Space 也就是像素空间,就是我们平常看到的正常的照片
像素空间内的,”E”与”D”,也就是stable diffusion webui里面的VAE
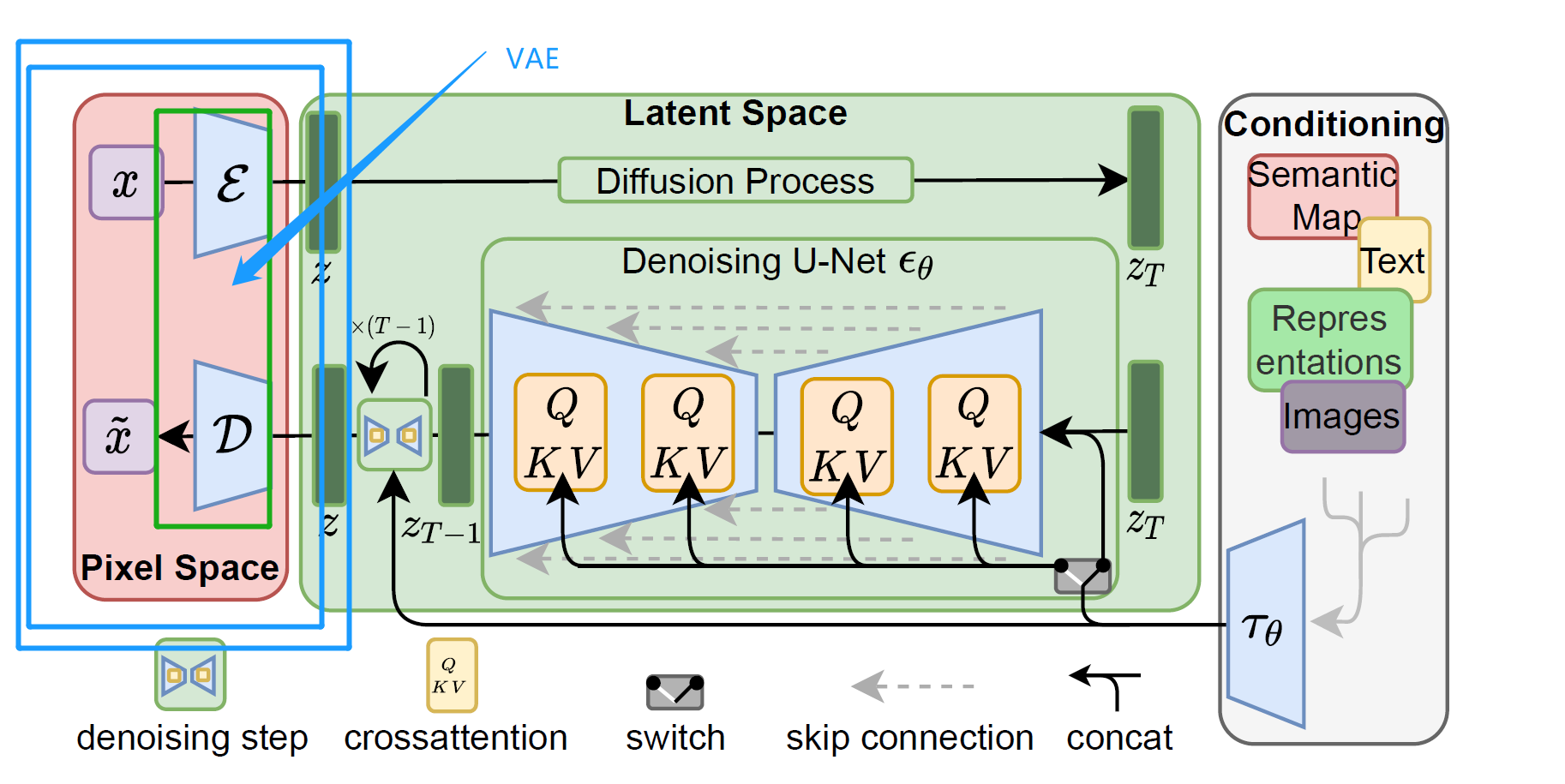
Latent Space
Latent Space ,也就是潜空间,里面包含了U-Net与denoising step
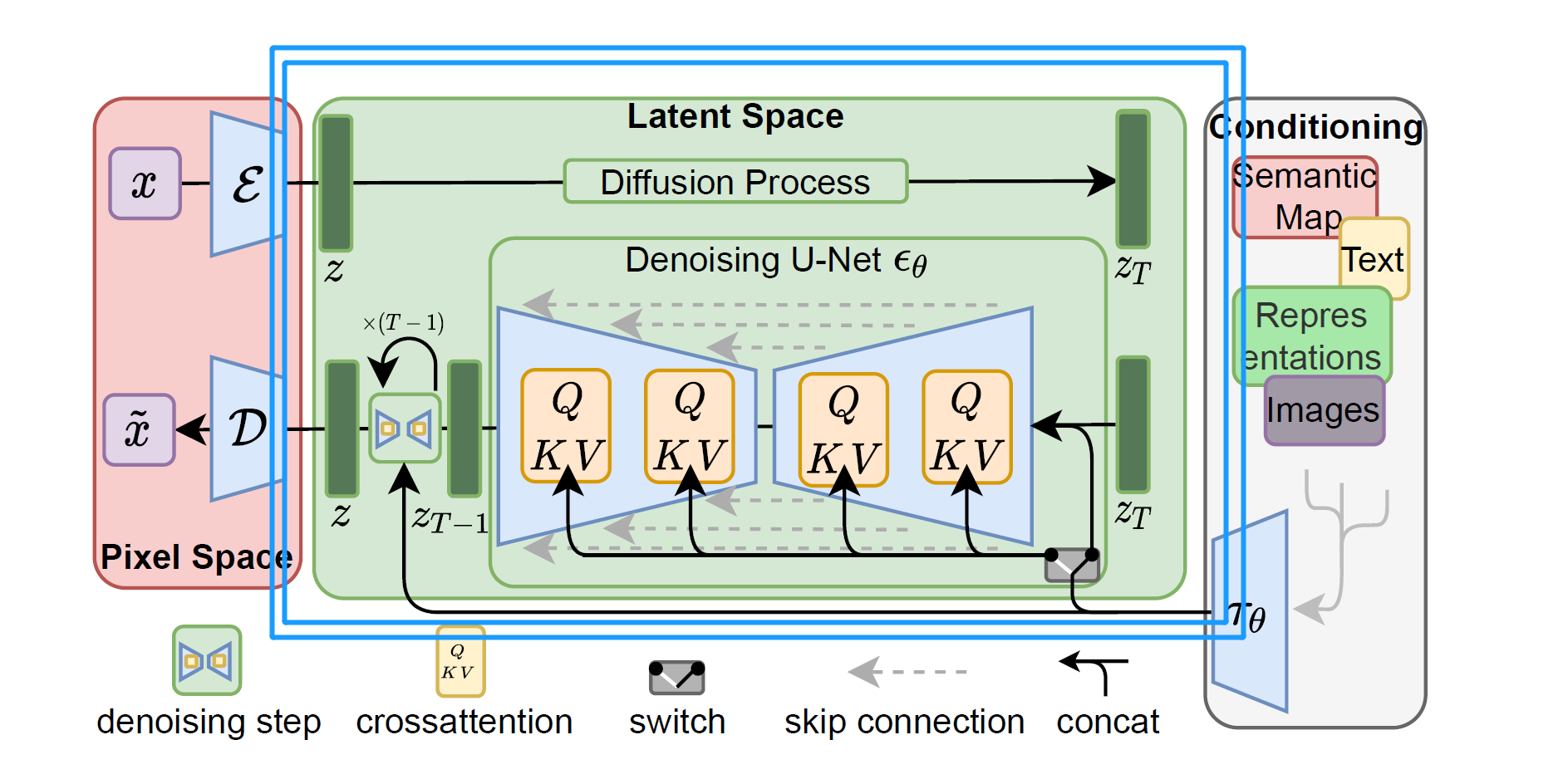
Conditioning
conditioning作为条件输入,包括平常输入的文本,都是在Conditioning层
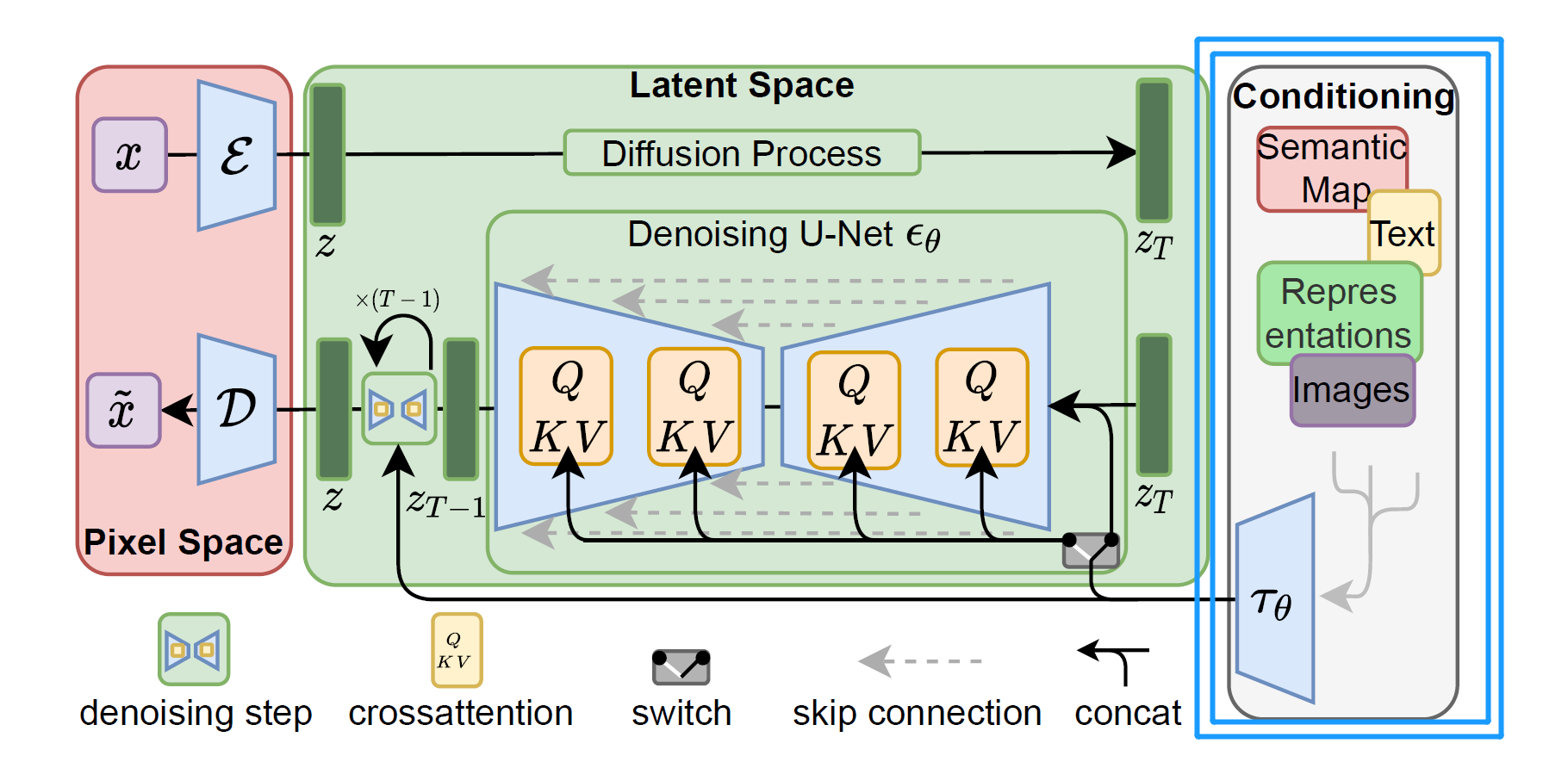
没有这部分内容,Stable Diffusion就不是文本到图像(text-to-image)模型。你会随机得到一只猫或一只狗的图像,但你没法控制Stable Diffusion为你生成猫或者狗的图像。
这就是条件**(conditioning)**的用武之地。条件的目的是引导噪声预测器,以便预测的噪声在图像中减去后会给出我们想要的东西。
扩散模型(Diffusion model)
一般来说,Stable Diffusion是一种文本到图像模式。给它一个文本提示(Text Prompt)。 它将返回与文本匹配的图像。这样是我们使用Stable Diffusion最常用的一个功能

Stable Diffusion属于一类称为扩散模型(diffusion model)的深度学习模型。它们是生成模型,这意味着它们的目的是生成类似于它们训练数据的新数据。对于Stable Diffusion来说,数据就是图像。
为什么叫扩散模型?因为它的数学看起来很像物理学中的扩散。让我们来解释这个理念。假设我训练了一个只有两种图像的扩散模型:猫和狗。在下图中,左边的两个山峰代表猫和狗这两组图像
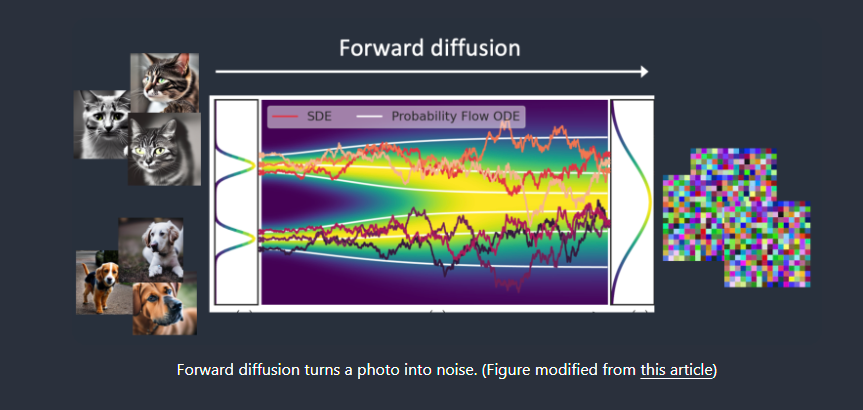
前向扩散(Forward diffusion)
前向扩散过程将噪声添加到训练图像中,逐渐将其转换为没有特点的噪声图像。前向过程会将任何猫或狗的图像变成噪声图像。最终,您将无法分辨它们最初是狗还是猫。就像一滴墨水掉进了一杯水里。墨滴在水中扩散。几分钟后,它会随机分布在整个水中。你再也分不清它最初是落在中心还是边缘附近。
下面是一个进行前向扩散的图像示例。猫的图像变成随机噪音。

反向/逆向扩散(Reverse diffusion)
如果我们能逆转扩散呢?就像向后播放视频一样。时光倒流。我们将看到墨滴最初添加的位置。
但是注意,我们从猫生成的噪声图,反向扩散后,可能会得到猫或者狗
从嘈杂、无意义的图像开始,反向扩散恢复了猫或狗的图像。这是主要思想。从技术上讲,每个扩散过程都有两部分:(1)漂移或定向运动和(2)随机运动。反向扩散向猫或狗的图像漂移,但两者之间没有任何变化。这就是为什么结果可以是猫或狗。
如何进行训练
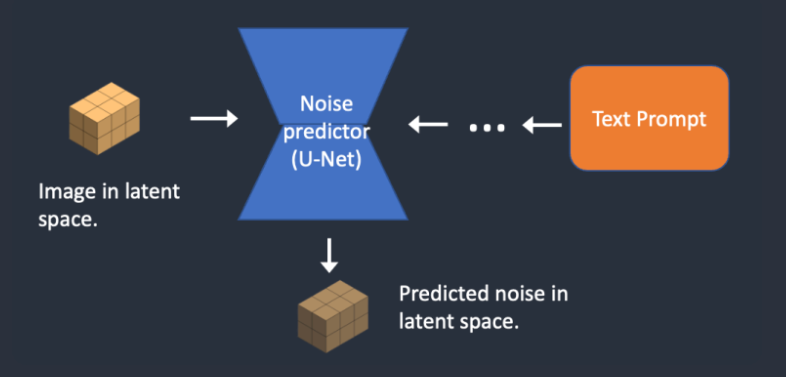
怎么能做到反向扩散呢?为了反向扩散,我们需要知道图像中添加了多少噪声。答案是教神经网络模型来预测增加的噪声。它被称为Stable Diffusion中的噪声预测因子(noise predictor)。这是一个U-Net模型。
培训如下。
- 选择一个训练图像,例如猫的照片。
- 生成随机噪声图像。
- 通过将此噪声图像添加到一定数量的步骤来损坏训练图像。
- 训练噪声预测器告诉我们添加了多少噪声。这是通过调整其权重并向其显示正确答案来完成的。

训练后,我们有一个噪声预测器,能够估计添加到图像中的噪声。
反向/逆向扩散(Reverse diffusion)
现在我们有了噪声预测器。要如何使用呢?
我们首先生成一个完全随机的图像,并要求噪声预测器告诉我们噪声。然后,我们从原始图像中减去这个估计的噪声。重复此过程几次。你会得到一只猫或一只狗的图像。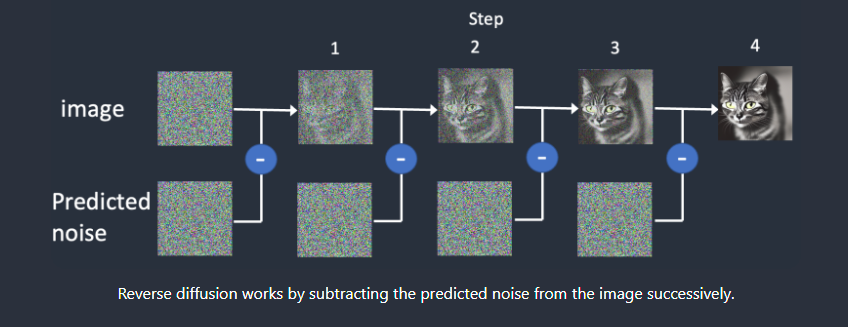
注意,若没有Conditioning,(条件输入))我们无法控制生成猫或狗的图像。当我们谈论条件反射时,我们将解决这个问题。目前,图像生成是无条件的。
潜在扩散模型(Latent diffusion model)
但是,我们上述讨论的噪声前向扩散与反向扩散,都是基于Pixel Space(像素空间)中运行,这导致了一个严重问题
** 在像素空间中,扩散的计算上非常非常慢**
基本上,在消费级显卡上,是不能通过走像素空间来生成噪声图的
Stable Diffusion在解决速度问题上使用的方法是:Latent Diffusion
Stable Diffusion是一种在潜在空间扩散(latent diffusion)的模型。它不是在高维图像空间中操作,而是首先将图像压缩到潜空间(latent space)中。对比原像素空间,潜空间(latent space)小了 48 倍(可以理解为被压缩过的空间),因此它获得了处理更少数字的好处,这就是为什么它要快得多。
Stable Diffusion模型的潜空间为4x64x64,比图像像素空间小48倍。我们谈到的所有正向和反向扩散实际上是在潜在空间中完成的。
因此,在训练过程中,它不会生成噪声图像,而是在潜在空间中生成随机张量(潜在噪声)。它不是用噪声破坏图像,而是用潜在噪声破坏图像在潜在空间中的表示。
条件(Conditioning)
文本条件(Text conditioning)
下面概述了如何处理文本提示(Text Prompt)并将其输入噪声预测器。分词器(Tokenizer)首先将提示中的每个单词转换为称为标记(token)的数字。然后将每个标记转换为称为Embedding的 768 值向量。然后,Embedding由文本转换器处理,并准备好供噪声预测器使用。
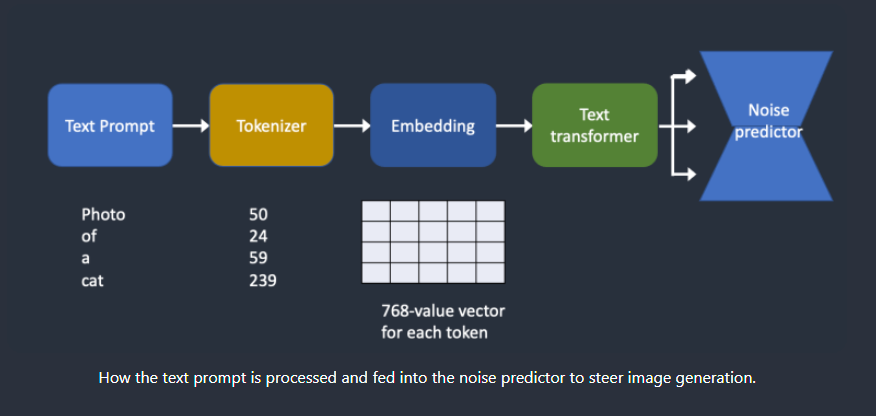
分词器(tokenizer)
令牌化(Tokenization)是计算机理解单词的方式。我们人类可以阅读单词,但计算机只能读取数字。这就是为什么文本提示中的单词首先转换为数字的原因。
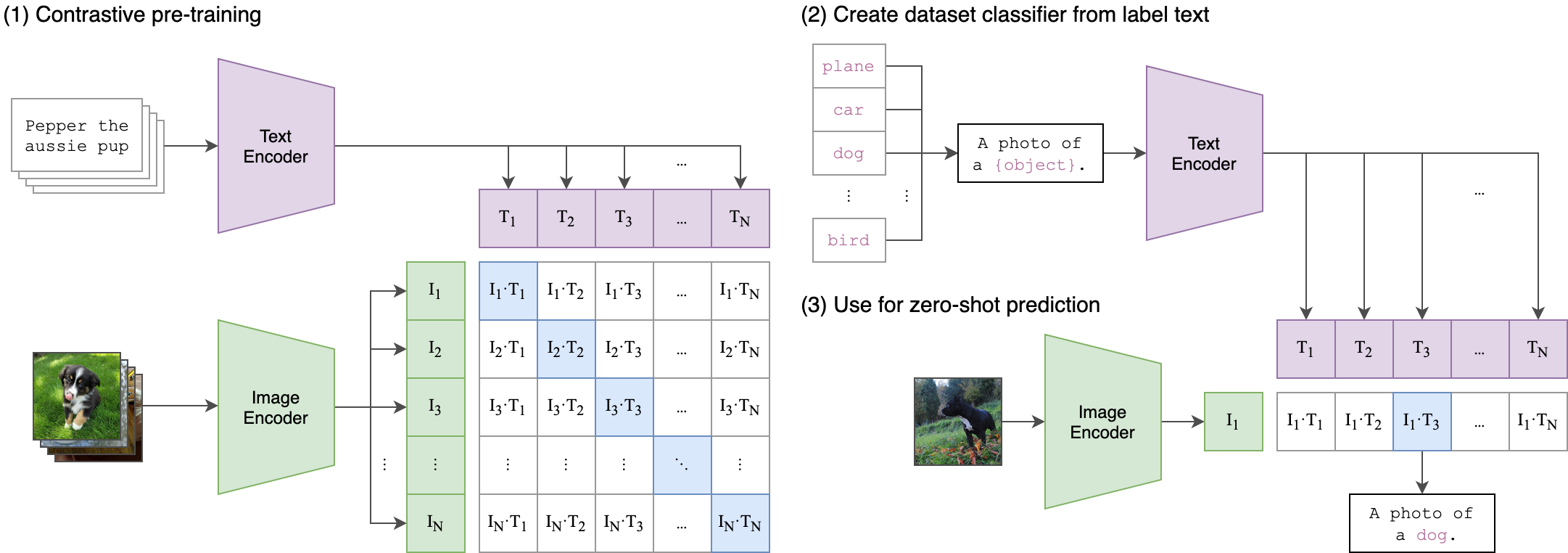
文本提示由Open AI开发的深度学习模型——CLIP进行标记
CLIP的英文全称是Contrastive Language-Image Pre-training,即一种基于对比文本-图像对的预训练方法或者模型。CLIP是一种基于对比学习的多模态模型,与CV中的一些对比学习方法如moco和simclr不同的是,CLIP的训练数据是文本-图像对:一张图像和它对应的文本描述,这里希望通过对比学习,模型能够学习到文本-图像对的匹配关系。如下图所示,CLIP包括两个模型:Text Encoder和Image Encoder,其中Text Encoder用来提取文本的特征,可以采用NLP中常用的text transformer模型;而Image Encoder用来提取图像的特征,可以采用常用CNN模型或者vision transformer。
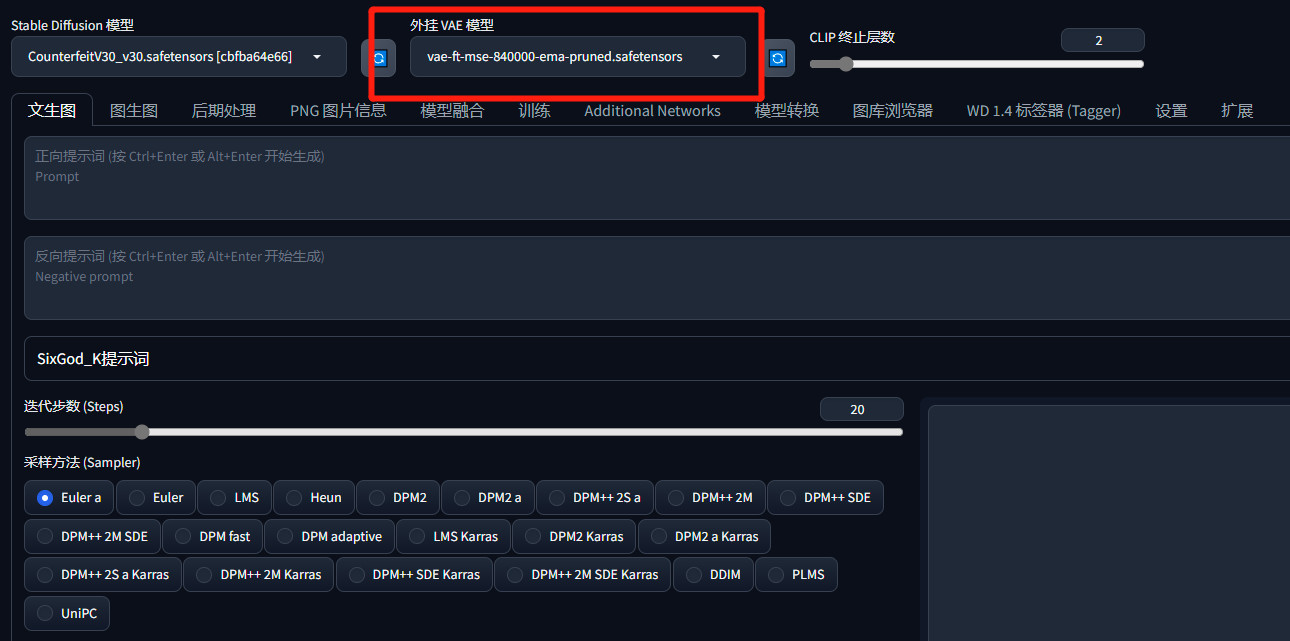
在stable diffusion中,我们在web-ui上方可以看到有一个”CLIP 终止层数”一般来说,我们不需要动这个东西,让他保持在2即可
分词器只能对它在训练期间看到的单词进行分词。例如,CLIP 模型中有”dream”和”beach”,但没有”dreambeach”。Tokenizer将”dreambeach”这个词分解为两个标记”dream”和”beach”。所以一个词并不总是意味着一个令牌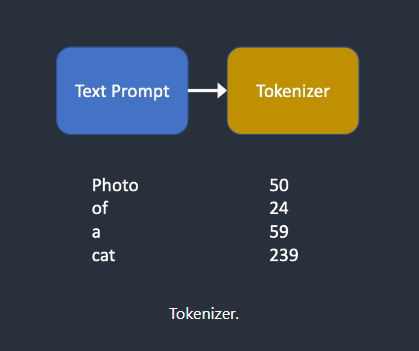
另一个细则是空格字符也是令牌(token)的一部分。在上述情况下,短语”dream beach”产生两个标记”dream “和”[空格]beach”。这些token与”dreambeach”产生的token不同,”dream beach”是”dream”和”beach”(beach前没有空格)。
嵌入/标签(Embedding)
嵌入是一个 768 个值的向量。每个令牌都有自己唯一的嵌入向量。嵌入由 CLIP 模型固定,该模型是在训练期间学习的。
为什么我们需要嵌入(Embedding)?这是因为有些词彼此密切相关。我们希望利用这些信息。例如,man、gentleman 和 guy 的嵌入几乎相同,因为它们可以互换使用。莫奈、马奈和德加都以印象派风格作画,但方式不同。这些名称具有接近但不相同的嵌入。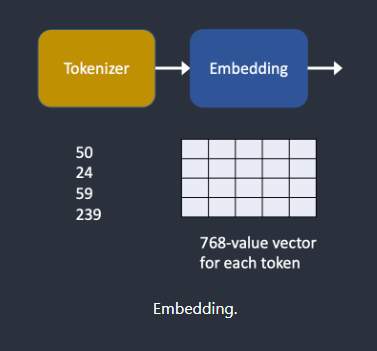
这与我们讨论的用于触发带有关键字的样式的嵌入相同。嵌入可以产生魔力。科学家们已经证明,找到合适的嵌入可以触发任意的对象和样式,这是一种称为文本反转的微调技术。
将嵌入(embeddings)馈送到噪声预测器(noise predictor)
在馈入噪声预测器之前,文本转换器需要进一步处理嵌入。变压器就像一个用于调节的通用适配器。在这种情况下,它的输入是文本嵌入向量,但它也可以是其他东西,如类标签、图像和深度图。转换器不仅进一步处理数据,而且还提供了一种包含不同调节模式的机制。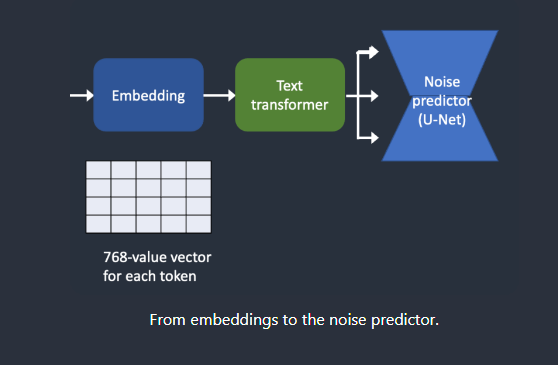
VAE(变分自编码器Variational Autoencoder)
VAE,即图像的编码器与解码器,他充当的是潜空间与像素空间的桥梁,负责将图像编码进入潜在空间。编码器将图像压缩为潜在空间中的低维表示。解码器从潜在空间恢复图像。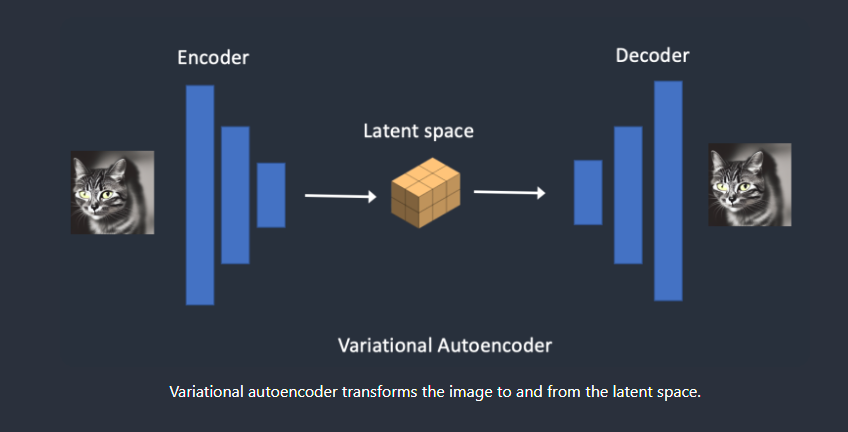
VAE可以将图像压缩到更小的潜在空间而不会丢失信息。原因是,自然图像不是随机的。它们具有很高的规律性:面部遵循眼睛、鼻子、脸颊和嘴巴之间的特定空间关系。狗有 4 条腿,是一种特殊的形状。
换句话说,图像的高维性是伪影。自然图像可以很容易地压缩到更小的潜在空间中,而不会丢失任何信息。这在机器学习中被称为流形假设(manifold hypothesis)。
不同的VAE,会对生成的图片有所影响,这里可以理解为,我们摄影的时候,使用不同的滤镜,出来的图片也不一样
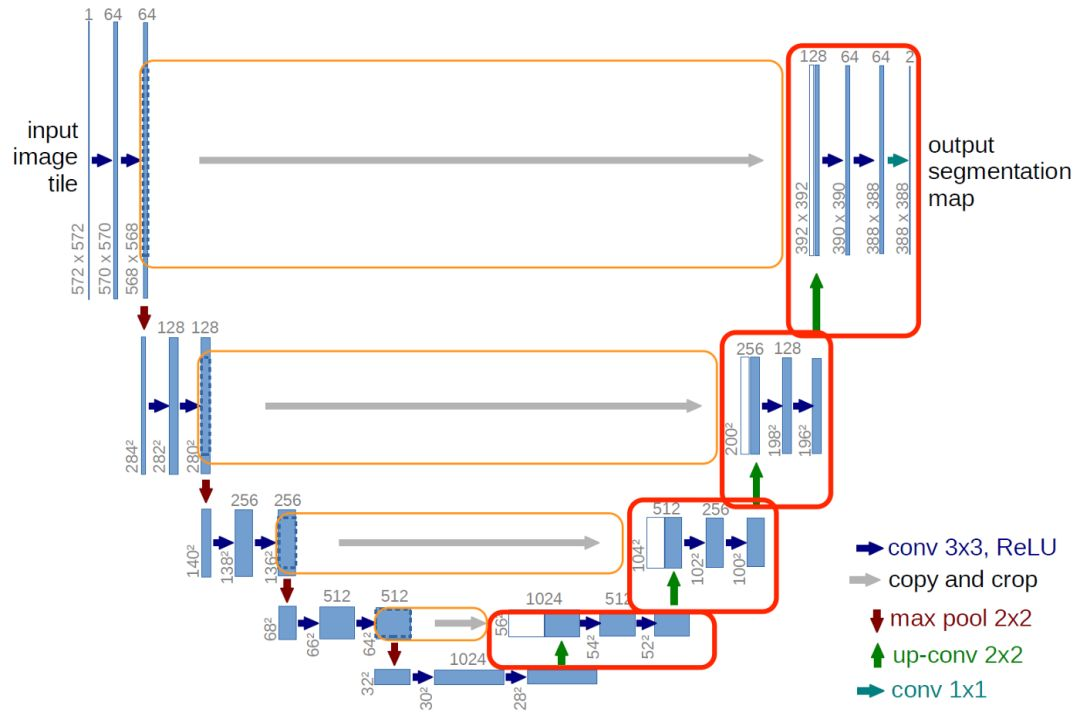
U-Net
U-Net是一种用于图像分割的深度学习架构,特别适用于医学图像分析领域。它的名字源自其网络结构的形状类似字母 “U”。U-Net包含一个编码器和一个解码器,编码器用于提取图像特征,解码器用于生成分割结果。在编码器部分,U-Net通过堆叠卷积层和池化层逐步压缩输入图像的空间分辨率和通道数,以提取高层次的特征信息。在解码器部分,U-Net通过反卷积层和跳过连接(skip connection)逐步恢复图像的分辨率,并将低层次的特征与高层次的特征融合,以生成准确的分割结果。U-Net的设计使得它能够处理具有不同尺寸和形状的图像,并具有较强的学习能力和分割精度。
在latent diffusion中,U-Net负责预测噪声
我们在使用时,我们输入文本text,text传入Q K V,即cross attention(交叉注意力层)
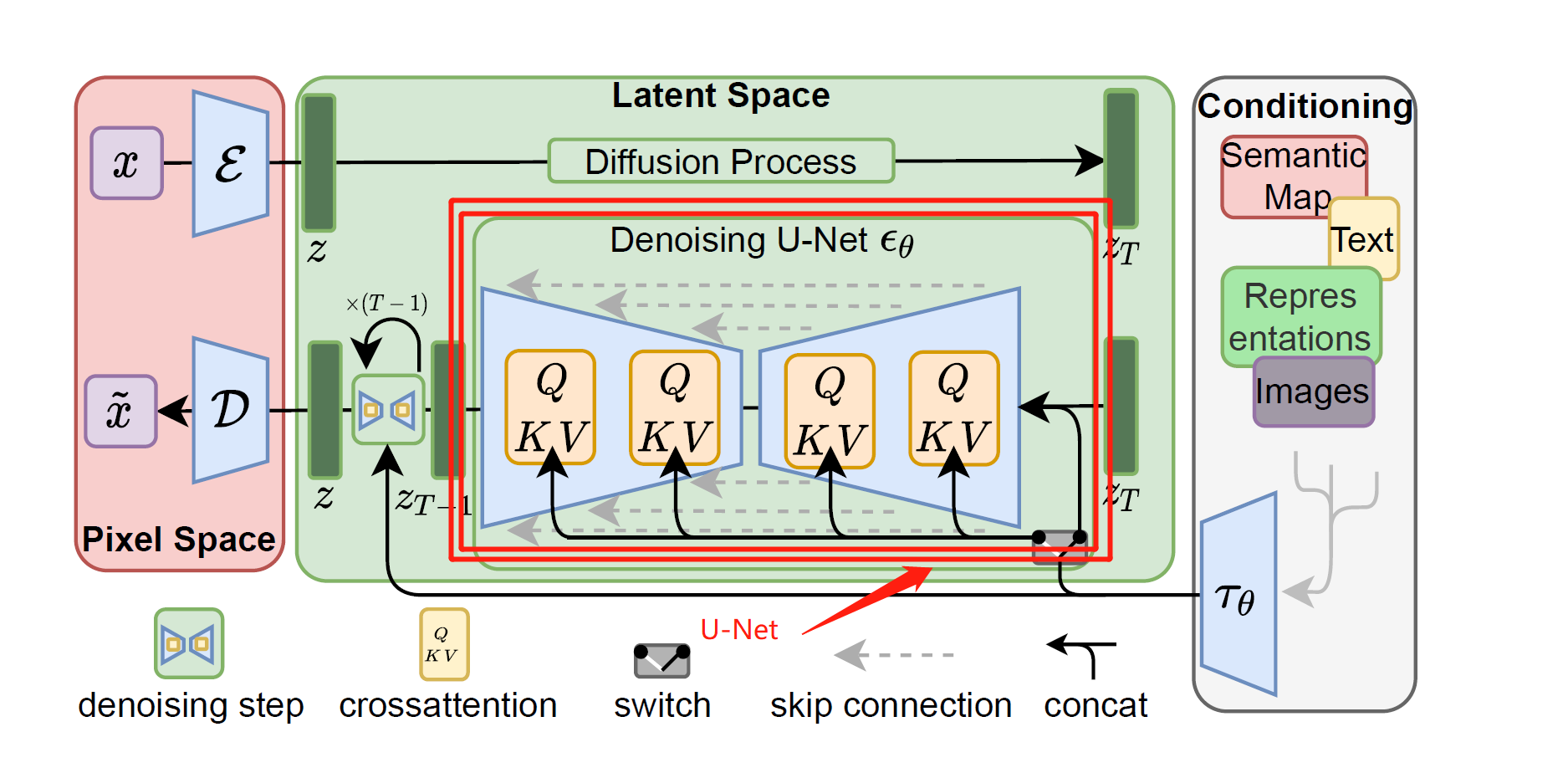
denoising step
Denoising(去噪)是指在机器学习中对数据进行降噪处理的步骤。在很多情况下,输入的数据可能受到噪声的干扰,包括随机误差、信号损失或其他干扰因素。这些噪声可能会使得数据不够清晰、混乱或者不准确,导致模型的训练和预测结果不够可靠。
在去噪步骤中,通常会使用一些特定的技术或模型来减少或消除数据中的噪声。常见的去噪方法包括滤波器、去噪自编码器和降噪卷积神经网络等。这些方法的目标是识别和分离出数据中的噪声,并尽可能保留或恢复原始数据中的有用信息。通过去噪处理,可以提高模型的准确性、稳定性和鲁棒性,从而提升机器学习任务的性能。
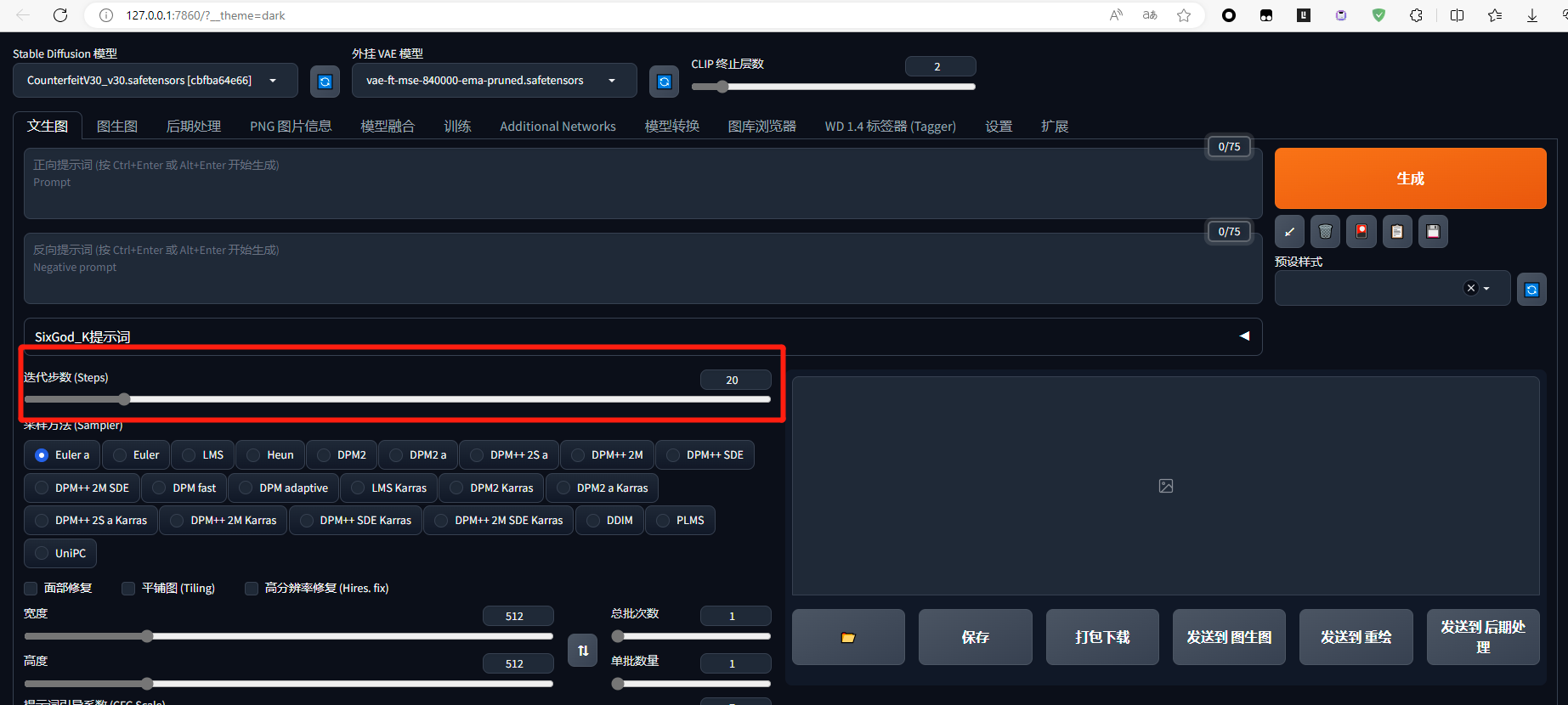
在stable diffusion中,denoising step即为迭代的次数,也就是在web-ui中的step/迭代步数
Stable Diffusion 文生图
在文本到图像中,您向Stable Diffusion提供文本提示(prompt),它会返回一个图像。
第一步
第 1 步,Stable Diffusion在潜空间中生成随机张量。您可以通过设置随机数生成器的种子来控制此张量。如果将种子设置为某个值,您将始终获得相同的随机张量。这是你在潜在空间中的图像。但现在都是噪音。
噪声图

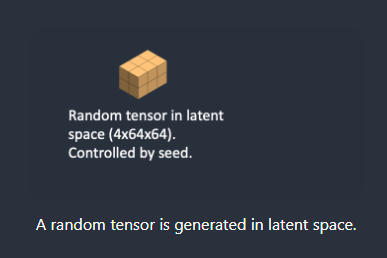
通过种子来控制噪声图,-1为随机种子
第二步
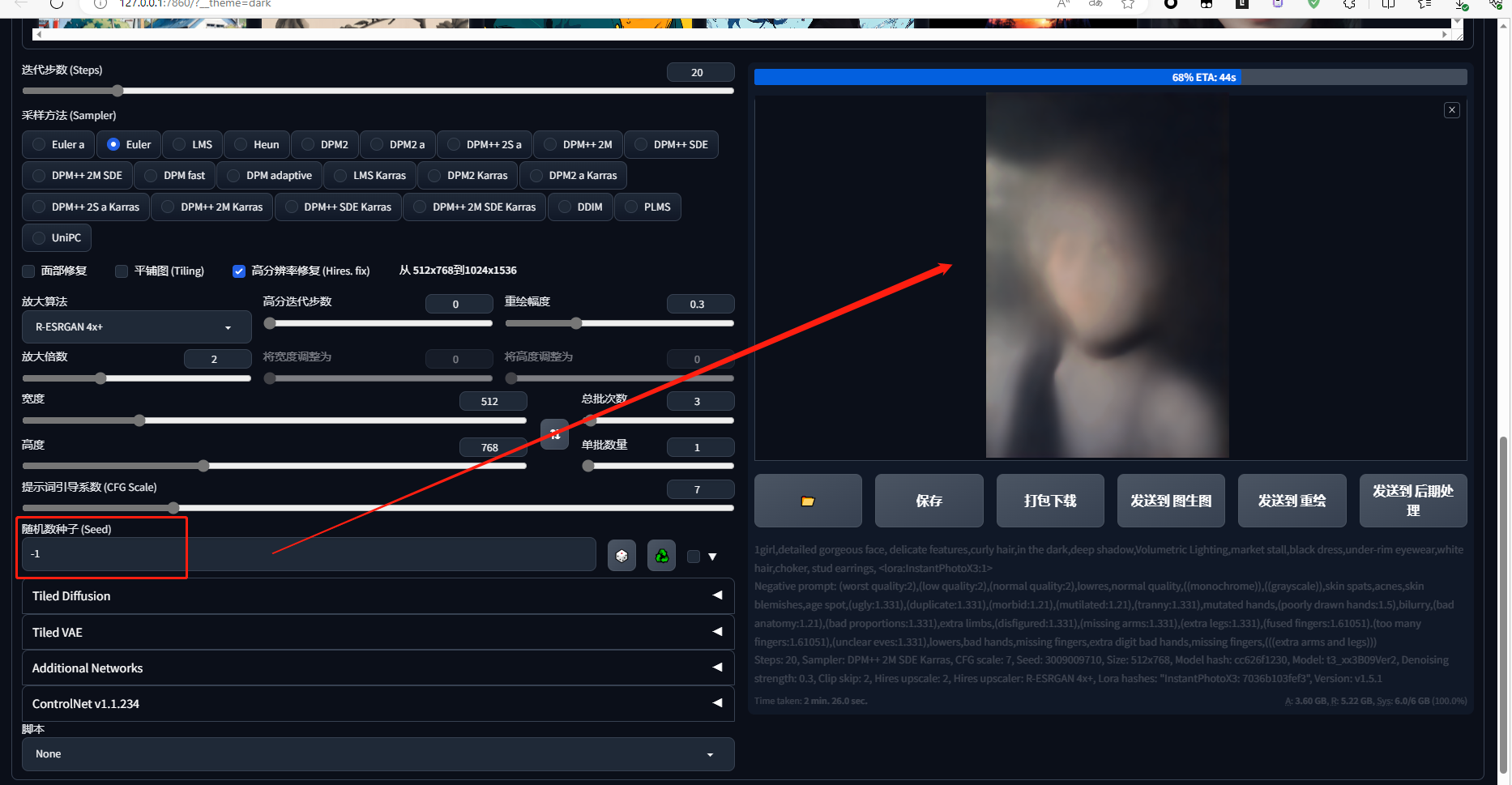
第 2 步,噪声预测器 U-Net 将潜在噪声图像和文本提示作为输入,并预测噪声,也在潜在空间(4x64x64 张量)中。
使用文本控制,将生成一个人物
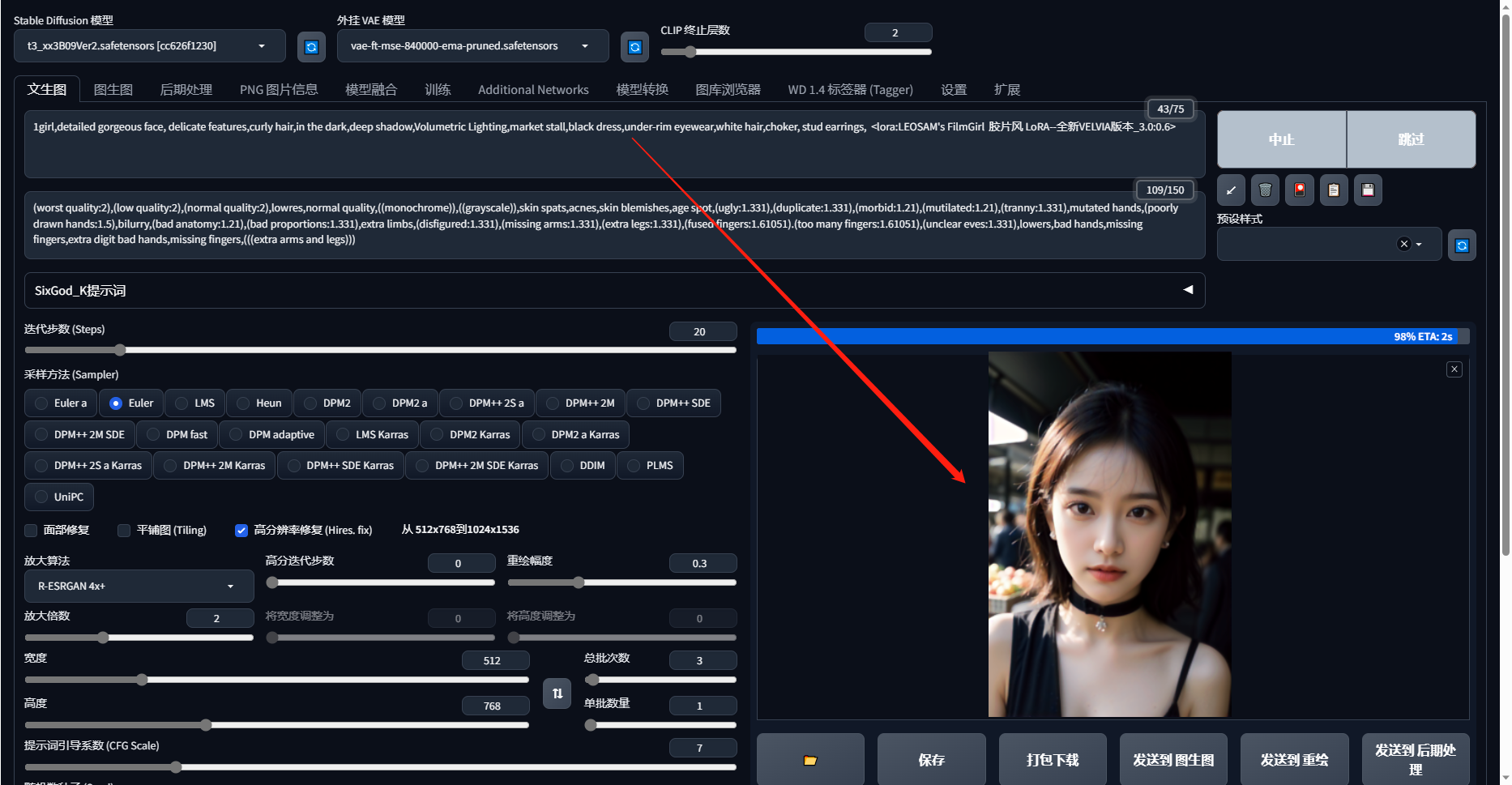
1 | 12 |
1 | 1girl,detailed gorgeous face, delicate features,curly hair,in the dark,deep shadow,Volumetric Lighting,market stall,black dress,under-rim eyewear,white hair,choker, stud earrings, 1女孩,细致华丽的脸庞,精致的五官,卷发,在黑暗中,深阴影,体积照明,市场摊位,黑色连衣裙,框下眼镜,白发,项链,耳钉, |
第三步
第3步,从潜在图像中减去潜在噪声。这将成为您的新潜在图像。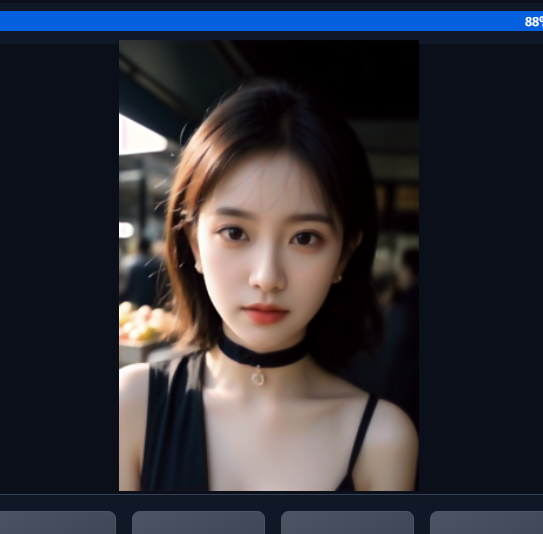
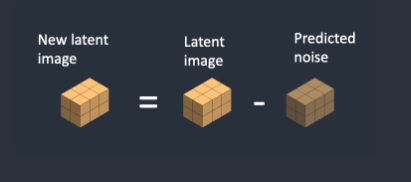
步骤 2 和 3 重复一定数量的采样步骤,例如 20 次。这就是上面所说的 step即 步数
第四步
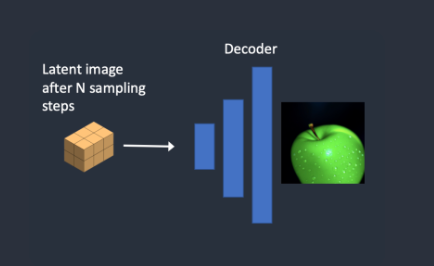
第 4 步,最后,VAE的解码器将潜在图像转换回像素空间。这是运行Stable Diffusion后获得的图像。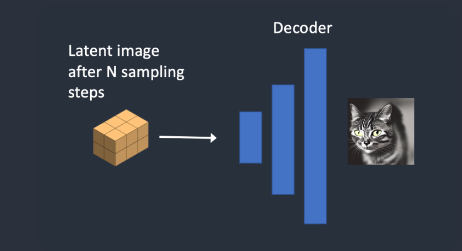
下面是一个完整的图像显示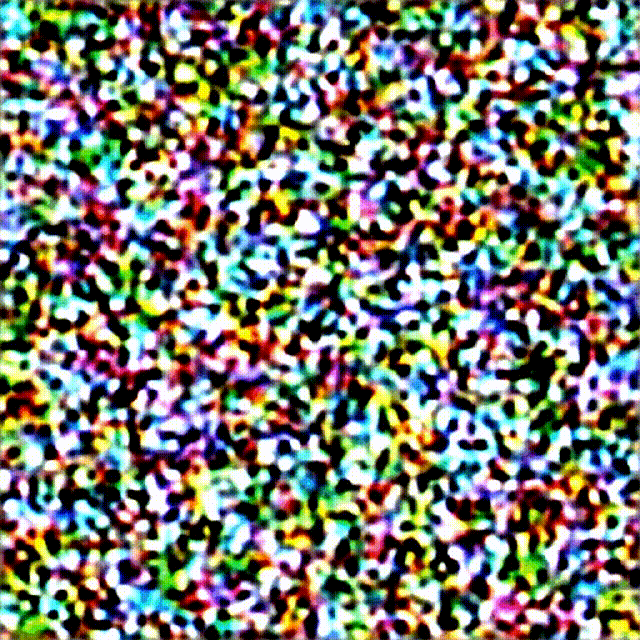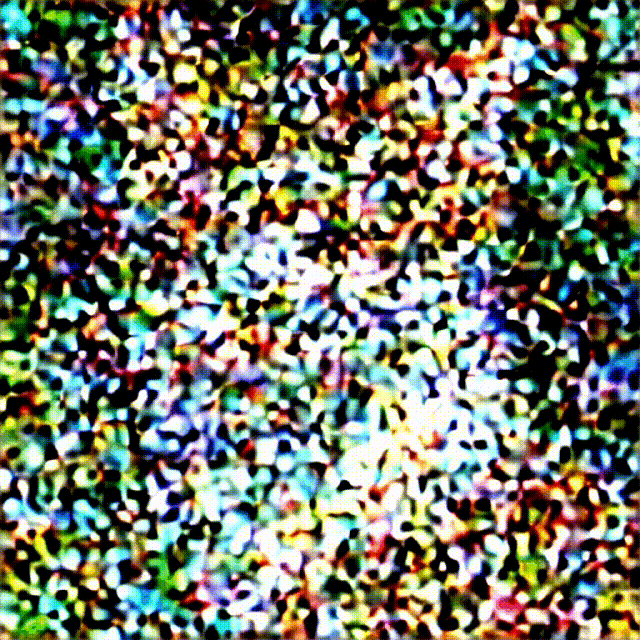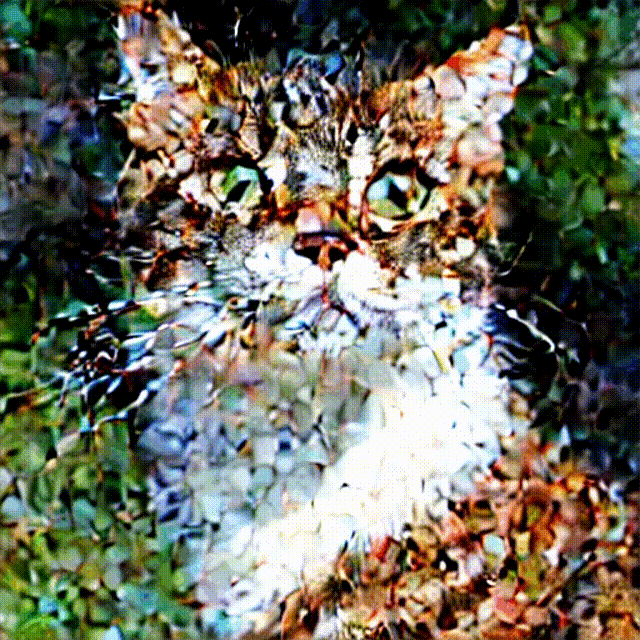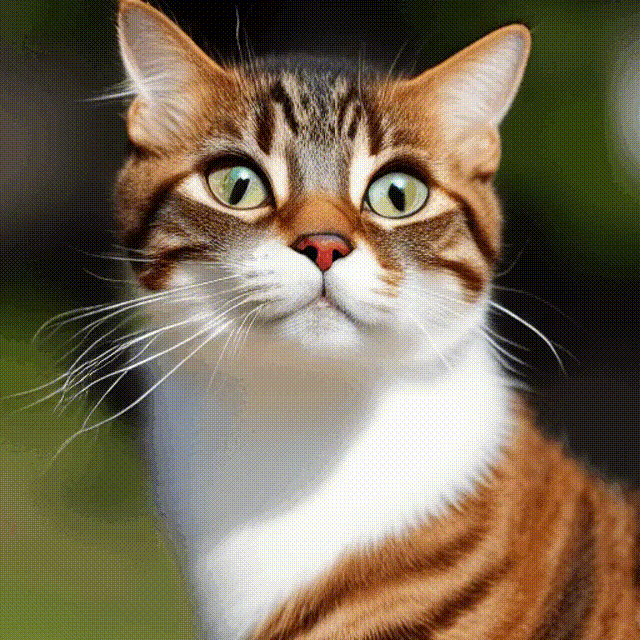
Stable Diffusion 图生图
图像到图像是SDEdit方法中首次提出的一种方法。SDEdit可以应用于任何扩散模型。所以我们有Stable Diffusion的图像到图像的功能。
输入图像和文本提示作为图像到图像的输入提供。生成的图像将由输入图像和文本提示调节。例如,使用这幅素人画和提示”photo of perfect green apple with stem, water droplets, dramatic lighting”作为输入,图像到图像可以将其变成专业绘图
第一步
第 1 步。输入图像被编码为潜在空间。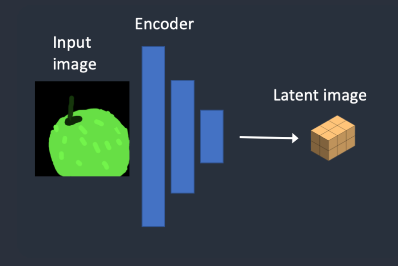
第二步
第 2 步。噪点被添加到潜在图像中。降噪强度控制添加的噪声量。如果为 0,则不添加噪声。如果为 1,则添加最大噪声量,以便潜在图像成为完整的随机张量。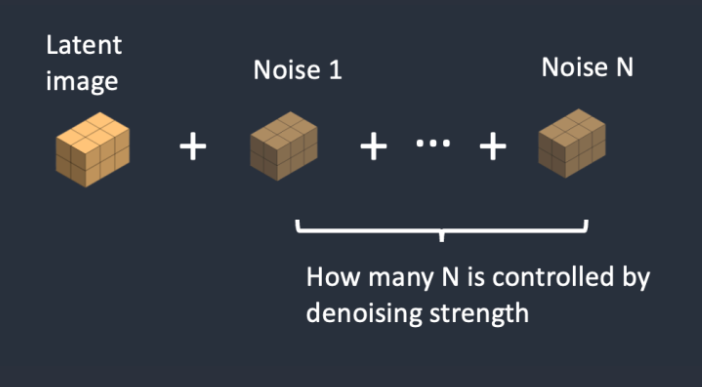
第三步
第 3 步。噪声预测器 U-Net 将潜在噪声图像和文本提示作为输入,并预测潜在空间(4x64x64 张量)中的噪声。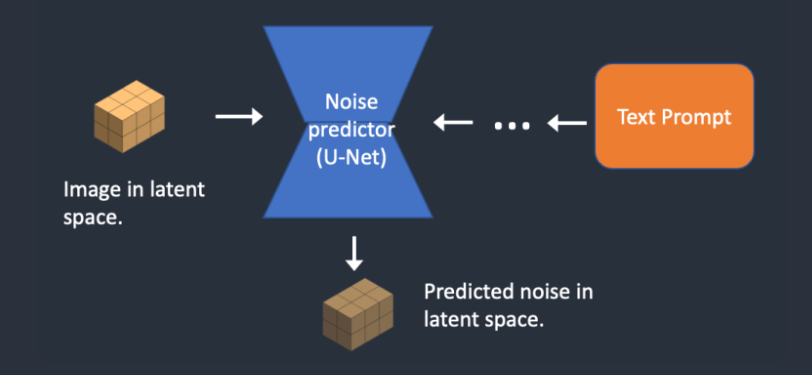
第四步
第 4 步。从潜在图像中减去潜在噪声。这将成为您的新潜在图像。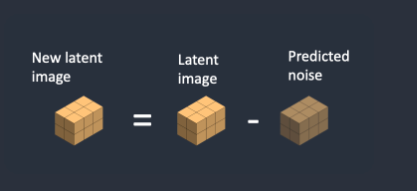
第五步
第5步。最后,VAE的解码器将潜在图像转换回像素空间。这是运行映像到映像后获得的图像。